

This issue is annoying us for years and happened today again after one year of being working.
XG 430 with lag and SFOS 19.5.3
XG has several VLAN. On one VLAN a Windows DHCP Server is serving DHCP addresses.
On several other VLAN configured also on XG there are DHCP forwarders pointing to the Windows DHCP server.
At some point the Clients will no longer receive DHCP offers and they do not get IP addresses anymore.
This situation only stops with a firewall reboot or when you delete any DHCP relay object on the XG and recreate it.
Then the clients will get IP addresses immediately.
Today it happened again I deleted a RED15 on the XG and powered on an other RED15W. Both have DHCP servers.
I have had several cased open since 2021 with GES and it cost a lot of time and frustration. They never found out anything helpful. Want us to reproduce the issue. But this is impossible - we have no idea how to reproduce it. We can only start logging and put logs to debug after it occoured.
Cases handling the issue were:
05521277 / direct to 2nd Level: XG DHCP server or DHCP relay failing after some time - clients not receiving DHCP offer
05158330 / 05128430 / XG DHCP server or DHCP relay failing after some time - clients not receiving DHCP offer
04704295 / XG DHCP server or DHCP relay failing after some time - clients not receiving DHCP offer
03953883 / DHCP Relay not working until deletion and recreation of a random DHCP Relay object
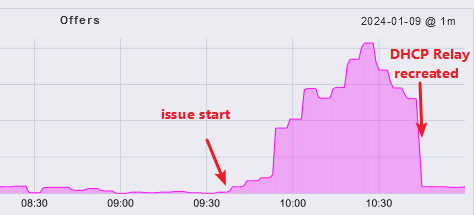
You can see on XG, it is not sending DHCPREPLY, this only starts again, when you recreated the dhcp relay
172.16.xxx.xxx is the Windows DHCP Server Relay IP address.
XG430_WP02_SFOS 19.5.3 MR-3-Build652 HA-Primary# tail -f networkd.log
udhcpc: sending discover
Forwarded BOOTREQUEST for 54:e1:ad:76:c0:f2 to 172.16.xxx.xxx
Forwarded BOOTREQUEST for ec:79:49:4e:99:57 to 172.16.xxx.xxx
Forwarded BOOTREQUEST for e8:80:88:54:61:5e to 172.16.xxx.xxx
udhcpc: sending discover
Forwarded BOOTREQUEST for e8:80:88:54:61:5e to 172.16.xxx.xxx
Forwarded BOOTREQUEST for 28:16:ad:3a:4c:83 to 172.16.xxx.xxx
Forwarded BOOTREQUEST for ec:79:49:4e:99:57 to 172.16.xxx.xxx
....
dhcp relay recreation
....
udhcpc: sending discover
Forwarded BOOTREQUEST for 60:5b:30:00:29:1f to 172.16.xxx.xxx
Forwarded BOOTREPLY for 60:5b:30:00:29:1f to 172.16.aaa.aaa
Forwarded BOOTREQUEST for 60:5b:30:00:29:1f to 172.16.xxx.xxx
Forwarded BOOTREPLY for 60:5b:30:00:29:1f to 172.16.aaa.aaa
Forwarded BOOTREQUEST for 60:5b:30:00:29:1f to 172.16.xxx.xxx
udhcpc: sending discover
Forwarded BOOTREQUEST for e4:46:b0:3a:04:0a to 172.16.xxx.xxx
Forwarded BOOTREPLY for e4:46:b0:3a:04:0a to 192.168.bbb.bbb
Forwarded BOOTREQUEST for e4:46:b0:3a:04:0a to 172.16.xxx.xxx
Forwarded BOOTREPLY for e4:46:b0:3a:04:0a to 192.168.bbb.bbb
udhcpc: sending discover
Added V19.5 MR3 TAG
[edited by: Erick Jan at 1:58 AM (GMT -8) on 10 Jan 2024]
[gesperrt von: LuCar Toni um 9:03 AM (GMT -7) am 23 Jul 2024]






