

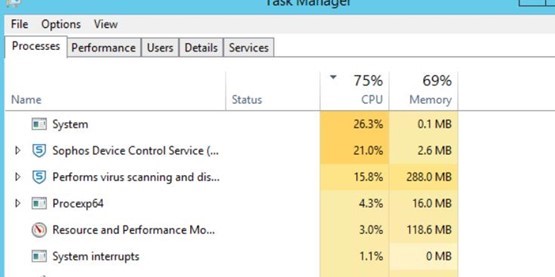
In our datacenter, we have a critical file share server that occasionally has performance spikes coming from two Sophos processes during peak business hours. We get alerted by users who reach out to us and report significantly slow performance when trying to access files users need to do their work. Sophos basically brings this server down to a halt, then for whatever reason after an hour or two seems to work itself out.
I have been monitoring the server for a little bit and noticed the Performs virus scanning and disinfection functions remain pretty consistent. This makes sense because users are heavily interacting with the files and folders there all the time. What does not make sense to me is why the Sophos Device Control Service is taking up 21% CPU. This seems to be the culprit for us. As of right now, the CPU for this process is sitting at 0% CPU.
For this server, we have scheduled scanning to kick off Tuesday night, so I know it is not related to that. If that process is tied to Peripheral Control Policy, we have it set to the Base Policy which has monitor everything. Does anyone have any suggestions or ways we can prevent that service from spiking up and causing a bottleneck in our network? It’s frustrating because Sophos suggested to follow this article KB-000036572 which doesn't help me with figuring out why this process randomly spikes.
Thanks in advance for any responses!
This thread was automatically locked due to age.


