

Hi Team,
My ASG 525 HA - 8.309 is taking too much time (unable to query the objects some time) to query the object - show where this object is in use and last change [IN network definition].
I have 1273 network definition hosts.
I'm thinking rebuild the database , is it gonna help me ??
/etc/init.d/postgresql rebuild => what would be the effect of this command ??
will its gonna effect my web security logs ??
Or anything else is the fix of this issue
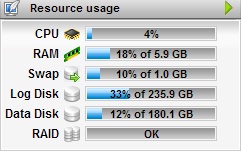
I have attached the snap of CPU & MEMORY UTILIZATION which is normal.
and also I'm continuously getting below mentioned logs in confd.log
var/HuirlwoAlxXZGpLqGpZh/downloads/singlelogfile/confd.log
2013:04:22-00:25:09 FW_INTRA_HO-2 confd[7872]: W main::cleanup_sessions:984() => id="3100" severity="warn" sys="System" sub="confd" name="timeout: removing session" sid="xLeXcQwSysmPCWFdBDQg"
2013:04:22-00:25:09 FW_INTRA_HO-2 confd[7872]: W main::cleanup_sessions:966() => id="3100" severity="warn" sys="System" sub="confd" name="removing corrupted session" sid="xLeXcQwSysmPCWFdBDQg.lock"
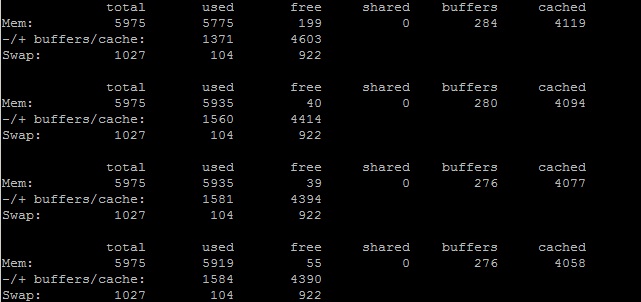
I have attached the snap of the query objects , which show that the process was stopped.
This thread was automatically locked due to age.




{kind=link}
{kind=link}
{kind=link}