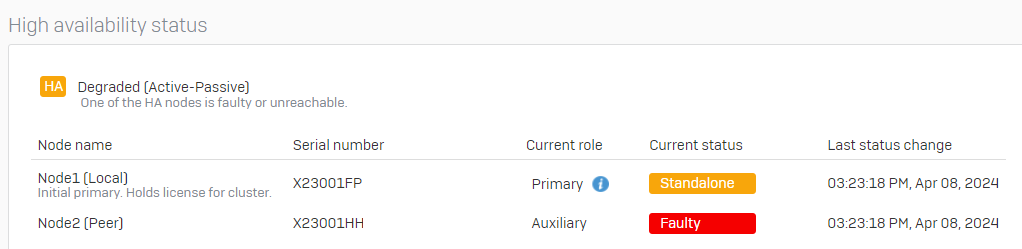
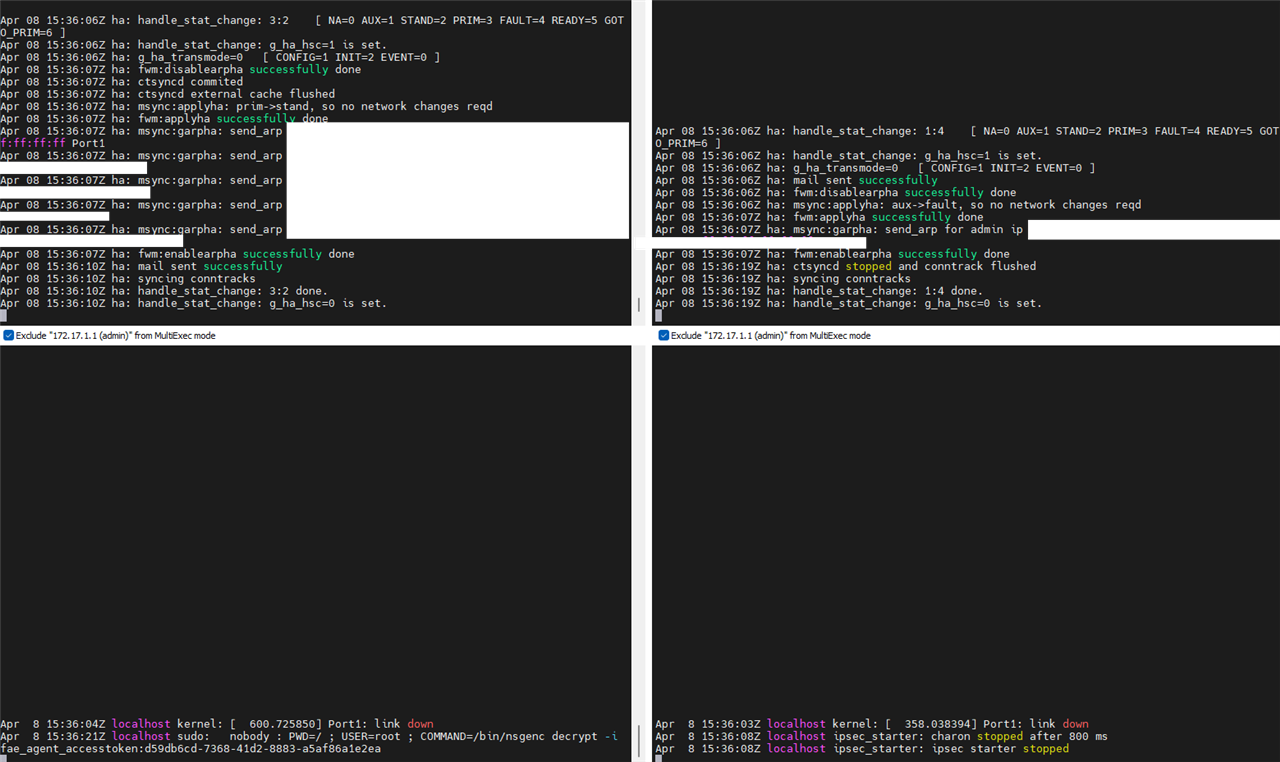
Whenever my LAN port switch restart my both the HA firewall restart why it happen
This thread was automatically locked due to age.
Important note about SSL VPN compatibility for 20.0 MR1 with EoL SFOS versions and UTM9 OS. Learn more in the release notes.
Whenever my LAN port switch restart my both the HA firewall restart why it happen