

Hi
After investigating on how to do the Up2Date-installation in an active/passive HA environment I finally felt safe doing it.
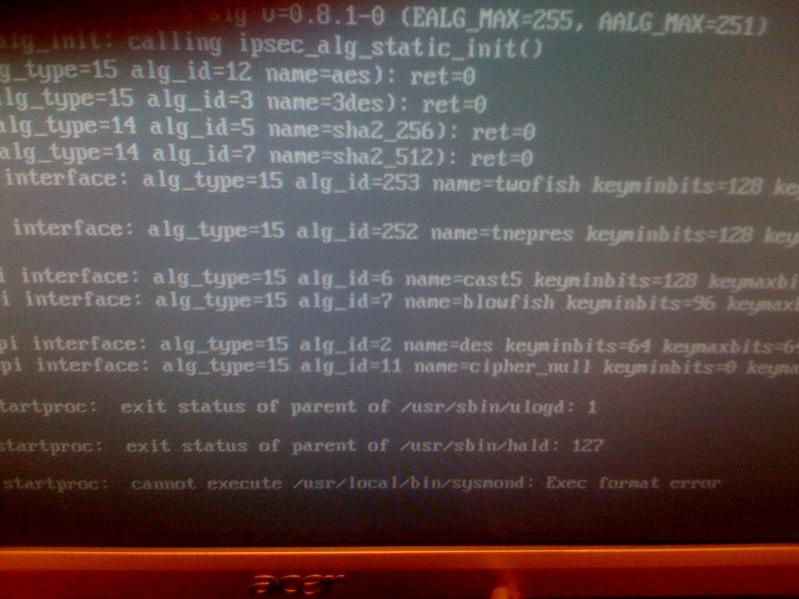
15 minutes after clicking "Upgrade to latest version now" I ended up with a DEAD slave. Now it has passed 30 minutes and still the SLAVE is dead.
The log says:
2010:02:17-22:14:35 (none) ha_daemon[3539]: id="38A2" severity="error" sys="System" sub="ha" name="Node 2 died during up2date process!"
2010:02:17-22:14:35 (none) ha_daemon[3539]: id="38C1" severity="info" sys="System" sub="ha" name="Node 2 is dead, received no heart beats!"
2010:02:17-22:14:37 (none) slon_control[3668]: Killing slon reporting [21816]
2010:02:17-22:14:37 (none) slon_control[3668]: Killing slon pop3 [21817]
2010:02:17-22:14:45 (none) ha_daemon[3539]: id="38A3" severity="debug" sys="System" sub="ha" name="Netlink: Lost link beat on eth5!"
2010:02:17-22:14:47 (none) ha_daemon[3539]: id="38A3" severity="debug" sys="System" sub="ha" name="Netlink: Found link beat on eth5 again!"
2010:02:17-22:14:56 (none) ha_daemon[3539]: id="38A3" severity="debug" sys="System" sub="ha" name="Netlink: Lost link beat on eth5!"
2010:02:17-22:14:57 (none) slon_control[3668]: Slon reporting exited with value 0!
2010:02:17-22:14:57 (none) slon_control[3668]: Slon pop3 exited with value 0!
2010:02:17-22:14:59 (none) ha_daemon[3539]: id="38A3" severity="debug" sys="System" sub="ha" name="Netlink: Found link beat on eth5 again!"
What am I doing wrong?
This thread was automatically locked due to age.


{kind=link}
{kind=link}