I'm hoping for some community help!
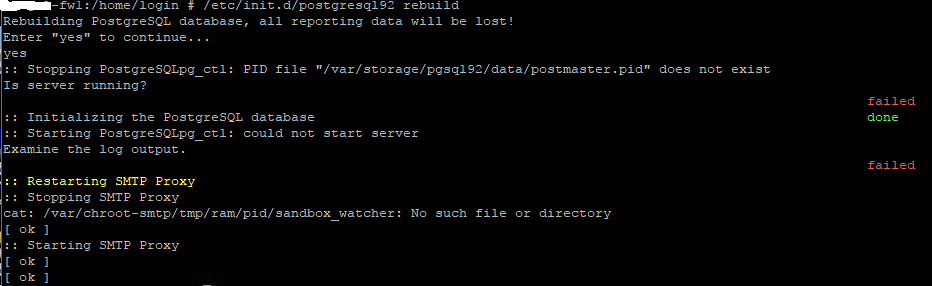
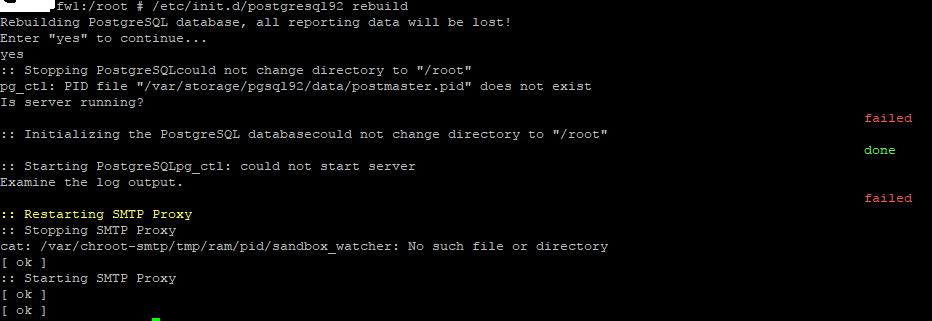
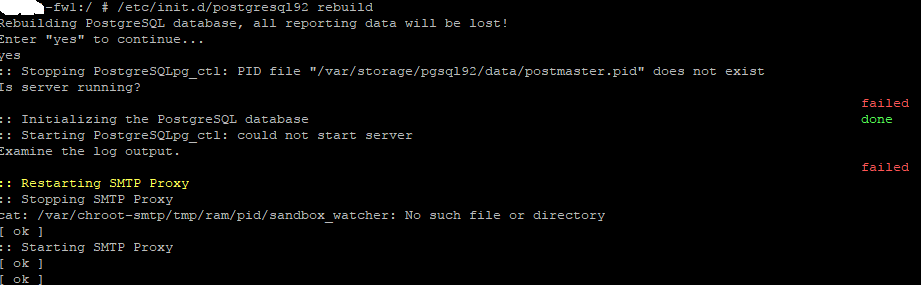
I recently transferred my configuration to new(er) hardware and in terms of performance/traffic it's running as expected. This was a clean install of 9.503-4 and my config was imported successfully during the initial wizard. The problem I'm having is that with the exception of my Log Files (todays and archived) I'm getting no reporting. Even the Dashboard Threat Status shows all zeros. The Log Partition Status shows all zeros, and only the 'Hardware' and 'Network Usage' pages show anything in graphs. I've also noticed that I'm no longer getting Executive reports although I do get other alert emails so I know my SMTP settings are correct. I tried to generate an ad hoc Executive Report on my gateway and it just spun without ever completing.
All of these pretty graphs and things worked on my old platform running the exact same code (though it wasn't a clean install... it was upgraded over time). I've tried rebooting but I'm not sure what else to do, other than possibly rush to install 9.504 but this doesn't seem to be a systemic issue with 9.503. The best matches for similar community posts were from 10+ years ago.
I will say FWIW that I am using remote syslog as well which is working correctly, and that isn't something that was added with this new install. The data is all there, it just doesn't seem to be getting parsed and presented properly. It feels like some sort of DB issue but I have no idea on how to go about troubleshooting/fixing that. I've tried the simple reboot to no avail.
Suggestions?
This thread was automatically locked due to age.