Hi,
I have a second hand SG 430, running with a home licence. Firmware version = 9.711-5. It has been running for over a year with no issues.
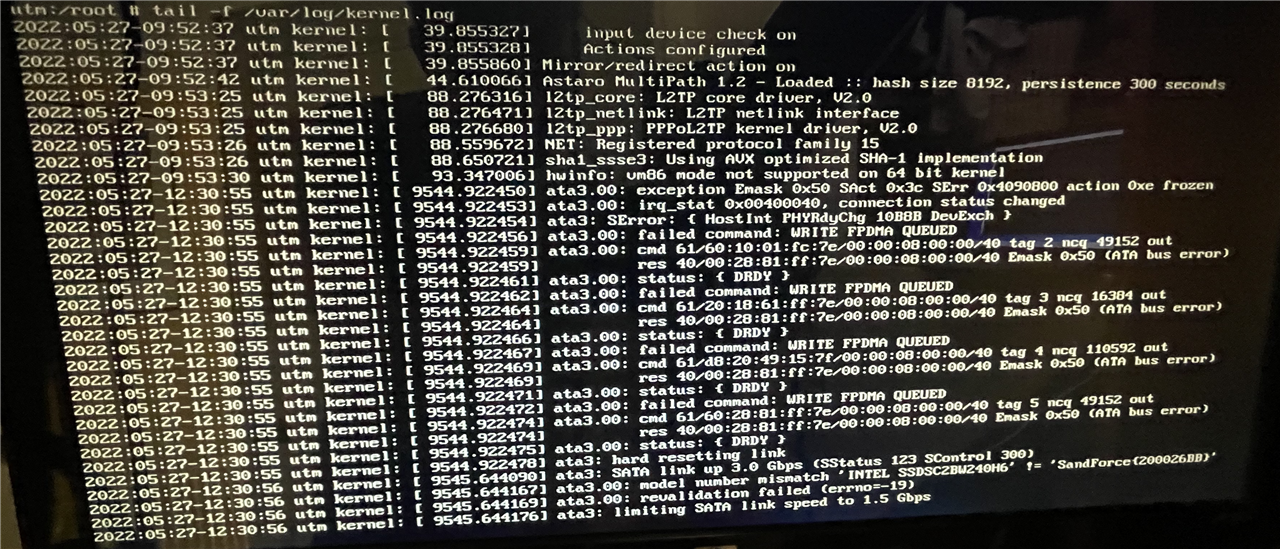
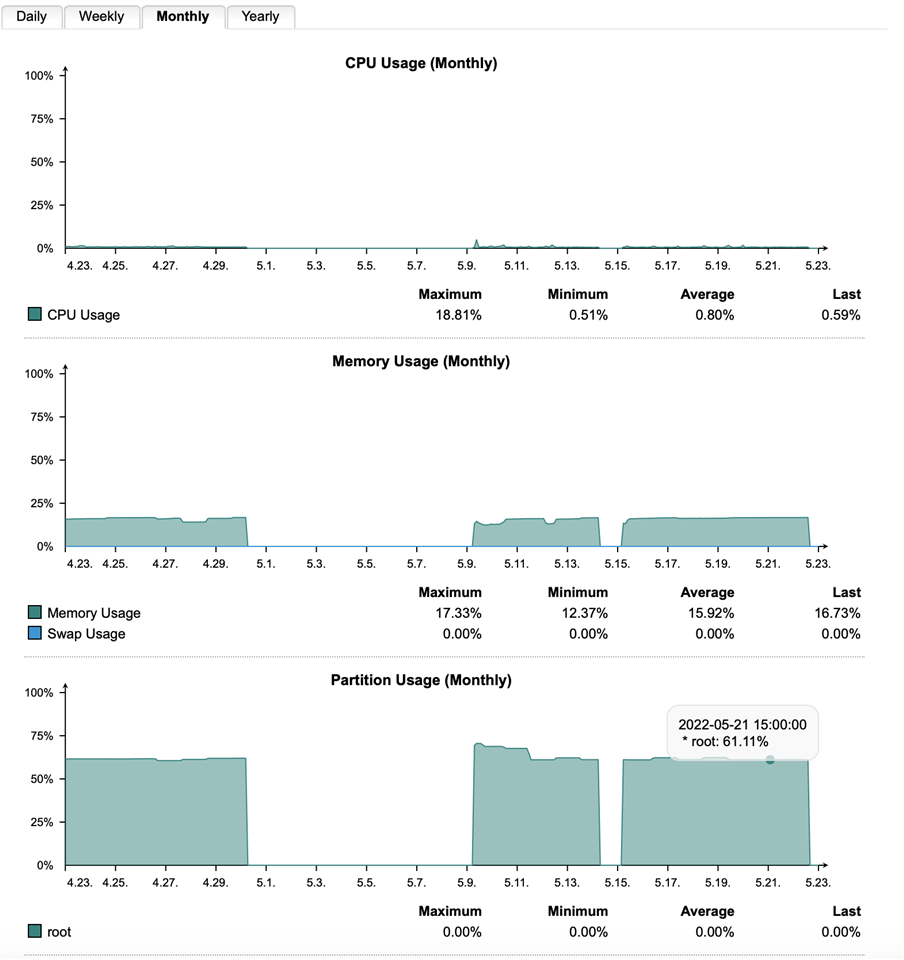
However, since the beginning of May, it has crashed/frozen 3 times. (see attached picture of hardware usage - 3rd time was today). When it freezes, WebAdmin is unavailable, internet access is unavailable, VPN is unavailable, etc. Even the joystick control on the front of the SG 430 doesn't do anything. Only way to fix is to power off at the wall and then power back on.
There seems to be no regularity to the crashes. I have checked the SMART status of the hard disk, which appears to have passed.
I'm wondering how to troubleshoot this issue? Is it likely to be a hardware or software issue? I'm thinking of completely re-installing UTM software, and then restoring configuration from Back-Up. Any advice would be greatly appreciated.
Many thanks
This thread was automatically locked due to age.