

Hello folks
I encountered a strange situation which I cannot resolve using backup/restore and/or clean re-install.
The Setup
I have a 2 node virtualized setup like in the attached simplified image. I'm using the home edition of Sophos UTM 9.405-5 and I wanted to setup an active/passive redundancy with near-identical VMs. In this setup, I would like FRW-1 to be the preferred master, because it runs on slightly more reliable hardware.
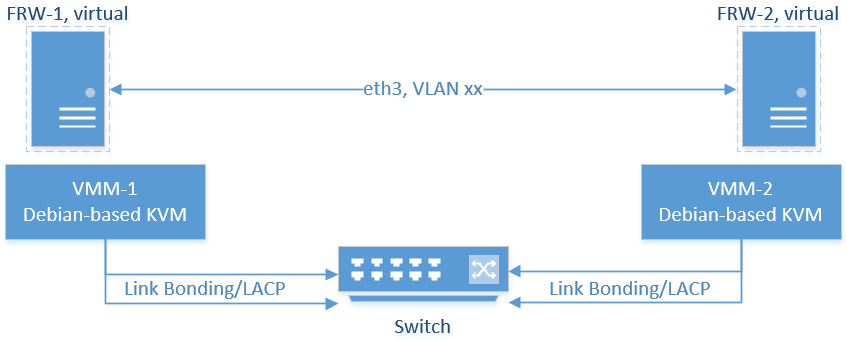
The VMs are completely unaware of any VLANs. The packets are being tagged by the host-machines. Also, all network interfaces are bonded via LACP using 2 physical NICs on each node.
As I understand it, the heartbeat/sync traffic should go over a dedicated interface on both Sophos appliances. No problem for me, they have even their very own VLAN tag number. Well, the dedicated interface is just a virtual NIC provided from the KVM host. Both VMs get the same number of interfaces with same VLAN tags and order, same disk sizes (20G), same amount of RAM (2.5G).
What did I do?
Installed UTM with 9.405-5 iso on FRW-2. Performed basic setup without license, assigned static IP address 10.20.20.12
On the running and active node (FRW-1, 10.20.20.1, UTM 9.405-5) in the HA section, I set the operation mode to "Automatic configuration" in the config tab, selected eth3 as the sync interface and applied it. Waited a few seconds. On the secondary node FRW-2 I did the same: automatic, eth3. I opened the live log of FRW-1 and the slave could be found.
What did I expect?
I expected FRW-2 to become a Slave node and being displayed on the master node in the HA section of WebAdmin. FRW-1 should become Master because of its longer uptime, and the WebAdmin connection to FRW-2 should terminate and disappear.
What was the result?
On FRW-1, the WebAdmin showed FRW-1 to be the Master node in the status tab. But there was no other node displayed, like not at all. Connection to FRW-2 remained on the same IP (10.20.20.12) and the status tab in its WebAdmin interface displayed both Nodes as Masters. The logs of FRW-2 had a lot of "Another master around!" entries.
So, FRW-1 sees FRW-2 for a brief moment, but then not anymore after connecting. FRW-2 sees FRW-1, but switches to Master role anyway.
Additional Information
The strange thing is, this setup worked before. 2 weeks ago I successfully set up a working HA configuration using same environmental conditions. However, VMM-2 encountered a hardware failure and had not been powered on for several days. I replaced its motherboard after the replacement arrived. For FRW-1 this didn't matter because it remained master anyway (as expected). It's just that I cannot re-initialize this kind of HA setup for some reason.
I tried to initialize manually, but with same results. I also reinstalled FRW-1 and FRW-2 using the older firmware 9.404-5, still same results.
General connection over the bonding works. Other VMs can happily ping and connect to each other without any issues.
I hope I'm missing something obvious and this is not some weird bug :P
Logs
So I rebooted the hypervisor just to be sure and tried again. These are the logs when configuring HA (automatic)
FRW-1:
These are the logs for FRW-2
This thread was automatically locked due to age.
