

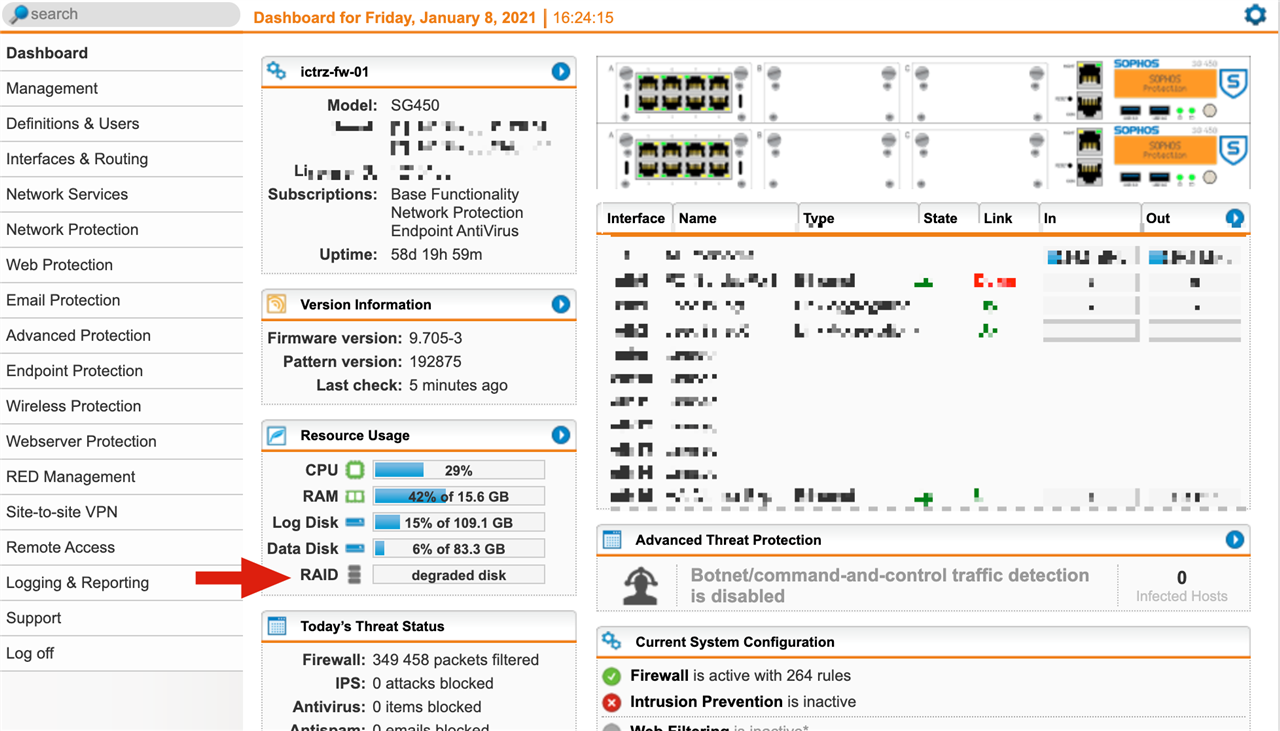
SG450 UTM shows RAID status as degraded.
Is there a way to check the status via CLI?
what i found so far is:
ictrz-fw-01:/home/login # lsblk
NAME MAJ:MIN RM SIZE RO MOUNTPOINT
sda 8:0 0 223.6G 0
├─md0 9:0 0 223.6G 0
│ ├─md0p1 259:0 0 350M 0 /boot
│ ├─md0p2 259:1 0 4G 0 [SWAP]
│ ├─md0p3 259:2 0 1.5G 0
│ ├─md0p4 259:3 0 1K 0
│ ├─md0p5 259:4 0 89G 0 /var/storage
│ ├─md0p6 259:5 0 5.4G 0 /
│ ├─md0p7 259:6 0 116.6G 0 /var/log
│ └─md0p8 259:7 0 4.7G 0 /tmp
└─md127 9:127 0 0
sdb 8:16 0 32K 0
should sdb have the same partition table as sda ?
further more we can see LOTS of fatal error messages (2gig per day) of the following message in the log:
2021:01:08-00:00:01 ictrz-fw-01-1 postgres[11853]: [3-1] FATAL: role "smtp" does not exist
2021:01:08-00:00:01 ictrz-fw-01-1 postgres[11855]: [3-1] FATAL: role "smtp" does not exist
2021:01:08-00:00:01 ictrz-fw-01-1 postgres[11865]: [3-1] FATAL: role "smtp" does not exist
2021:01:08-00:00:01 ictrz-fw-01-1 postgres[11867]: [3-1] FATAL: role "smtp" does not exist
2021:01:08-00:00:01 ictrz-fw-01-1 postgres[11877]: [3-1] FATAL: role "smtp" does not exist
2021:01:08-00:00:01 ictrz-fw-01-1 postgres[11879]: [3-1] FATAL: role "smtp" does not exist
I assume that the database is corrupt and thus the disks are heavily in use. could that be the root cause?
This thread was automatically locked due to age.
