

I recently updated from our cluster from 9.701 to 9.703. In order to have a failback I only updated one node1 (reserve ...) and updated the second node one day later.
Everything looks fine however I regularly got the following mail from the slave:
RED server not running - restarted
--
HA Status : HA SLAVE (node id: 1)
System Uptime : 0 days 6 hours 58 minutes
System Load : 0.97
System Version : Sophos UTM 9.703-3
Please refer to the manual for detailed instructions.
After another reboot of the slave this has changed to:
Log Disk is filling up - please check. Current usage: 91%
--
HA Status : HA SLAVE (node id: 1)
System Uptime : 0 days 6 hours 40 minutes
System Load : 0.46
System Version : Sophos UTM 9.703-3
Please refer to the manual for detailed instructions.
The logfile of the master is below 90% and the settings for the logfiles are 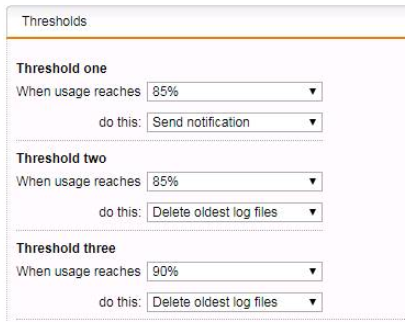
There was no issue before the update.
I think master and slave have been switched during the process:
- Old slave was updated. Changed to the new master.
- Old master became slave was put in reserve, then updated being still be slave.
Aren't the logfiles synchronized?
What can be done to get rid of these messages?
This thread was automatically locked due to age.
