Hello,
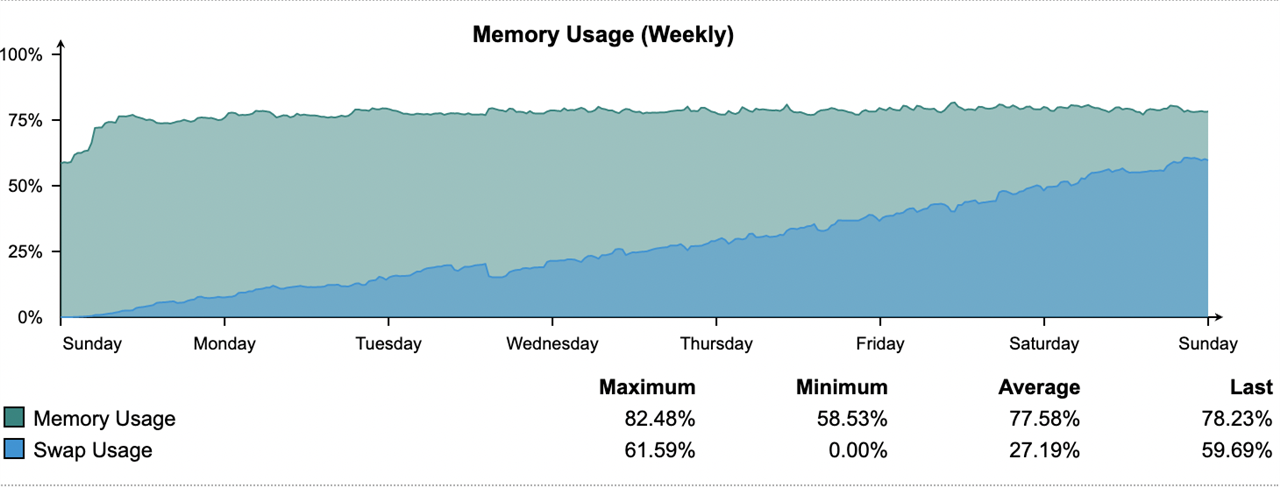
I have a pair of virtual UTMs which have run for years with about 4G of RAM allocated to them. After the upgrade from 9.712 to 9.713 in Nov I noticed my swap usage climbing beyond its normal 10-15% level. The culprit was the httpproxy proces so I added about 1/2G to the VMs which returned the swap usage to about 15%. This past week I updated to 9.714 and observed the httpproxy process growing much larger driving swap usage into the 60% range.
The two systems run with almost identical configurations which change very little over time. Our usage patterns have not changed much either. I have not noticed anything in the release notes suggesting a significant change that should require more memory, so my suspicion at this point is that the httpproxy process has a memory leak.
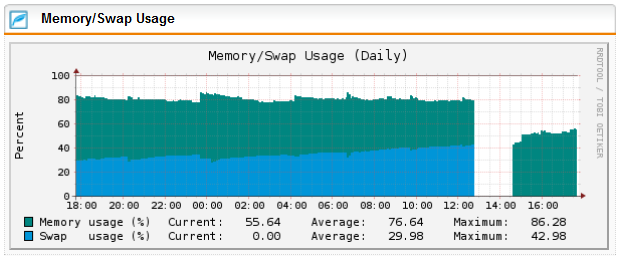
The graph below shows 9.714 after a restart last week. Here is the current httpproxy memory/swap usage:
PID USER PR NI VIRT RES SHR S %CPU %MEM TIME+ SWAP COMMAND
4776 httpprox 20 0 6202m 1.6g 3996 S 1 38.4 46:09.01 4.4g httpproxy
--Larry
This thread was automatically locked due to age.