

I updated from 9.605-1 to 9.705-3 one Node in HA Cluster yesterday. After HA Switch is my CPU usage on upgrade Node about 75%, i have no connection to the network over bridged interface (State: up, Link: down) and in HA Log there is no connection to postgres on master.
After failover to reserverd (9.605-1) Node i have similar CPU Usage about 70-75% and the connection to the network over the bridged interface is ok (state: up, Link: up).
After several Reboots and HA Switchover there is no improvement.
Hier some screenshots from reserved Node (Master) with older Firmware 9.605-1
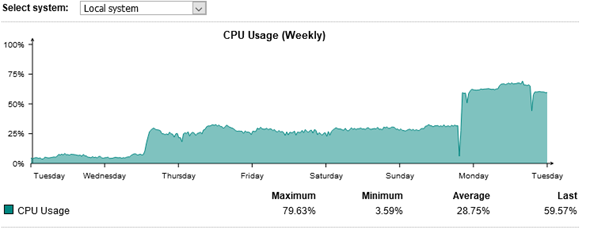
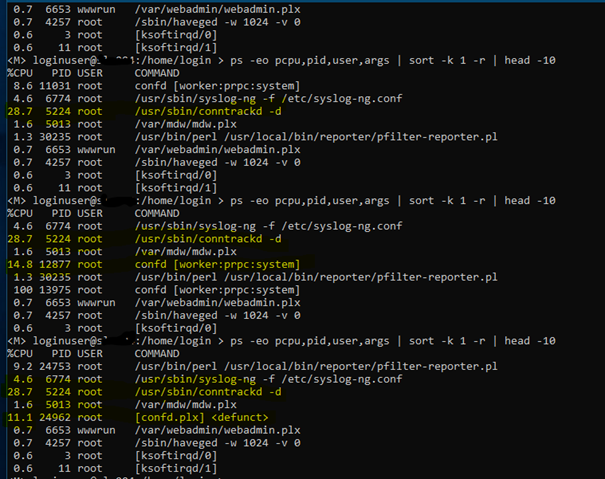
HA-Log
------------------------------
2021:03:09-23:15:36 xxxxxx-1 ha_mode[21096]: calling check
2021:03:09-23:15:36 xxxxxx-1 ha_mode[21096]: check: waiting for last ha_mode done
2021:03:09-23:15:36 xxxxxx-1 ha_mode[21096]: check_ha() role=MASTER, status=UNLINKED
2021:03:09-23:15:36 xxxxxx-1 ha_mode[21096]: check done (started at 23:15:36)
2021:03:09-23:15:51 xxxxxx-1 repctl[4936]: [e] db_connect(2203): timeout while connecting to database(DBI:Pg:dbname=repmgr;host=198.19.250.2)
2021:03:09-23:15:51 xxxxxx-1 repctl[4936]: [e] master_connection(2045): (timeout)
2021:03:09-23:15:51 xxxxxx-1 repctl[4936]: [i] main(188): cannot connect to postgres on master, retry after 1024 seconds
2021:03:09-23:18:44 xxxxxx-2 repctl[4844]: [e] db_connect(2203): timeout while connecting to database(DBI:Pg:dbname=repmgr;host=198.19.250.1)
2021:03:09-23:18:44 xxxxxx-2 repctl[4844]: [e] master_connection(2045): (timeout)
2021:03:09-23:18:44 xxxxxx-2 repctl[4844]: [i] main(188): cannot connect to postgres on master, retry after 1024 seconds
2021:03:09-23:33:25 xxxxxx-1 repctl[4936]: [e] db_connect(2203): timeout while connecting to database(DBI:Pg:dbname=repmgr;host=198.19.250.2)
2021:03:09-23:33:25 xxxxxx-1 repctl[4936]: [e] master_connection(2045): (timeout)
2021:03:09-23:33:25 xxxxxx-1 repctl[4936]: [i] main(188): cannot connect to postgres on master, retry after 1024 seconds
2021:03:09-23:36:18 xxxxxx-2 repctl[4844]: [e] db_connect(2203): timeout while connecting to database(DBI:Pg:dbname=repmgr;host=198.19.250.1)
2021:03:09-23:36:18 xxxxxx-2 repctl[4844]: [e] master_connection(2045): (timeout)
2021:03:09-23:36:18 xxxxxx-2 repctl[4844]: [i] main(188): cannot connect to postgres on master, retry after 1024 seconds
2021:03:09-23:45:36 xxxxxx-2 ha_daemon[4794]: id="38A0" severity="info" sys="System" sub="ha" seq="S: 94 36.993" name="Executing (wait) /usr/local/bin/confd-setha mode slave master_ip 198.19.250.1 slave_ip 198.19.250.2"
2021:03:09-23:45:37 xxxxxx-2 ha_daemon[4794]: id="38A0" severity="info" sys="System" sub="ha" seq="S: 95 37.099" name="Executing (nowait) /etc/init.d/ha_mode check"
2021:03:09-23:45:37 xxxxxx-2 ha_mode[19632]: calling check
2021:03:09-23:45:37 xxxxxx-2 ha_mode[19632]: check: waiting for last ha_mode done
2021:03:09-23:45:37 xxxxxx-2 ha_mode[19632]: check_ha() role=SLAVE, status=RESERVED
2021:03:09-23:45:37 xxxxxx-2 ha_mode[19632]: check done (started at 23:45:37)
2021:03:09-23:50:59 xxxxxx-1 repctl[4936]: [e] db_connect(2203): timeout while connecting to database(DBI:Pg:dbname=repmgr;host=198.19.250.2)
2021:03:09-23:50:59 xxxxxx-1 repctl[4936]: [e] master_connection(2045): (timeout)
2021:03:09-23:50:59 xxxxxx-1 repctl[4936]: [i] main(188): cannot connect to postgres on master, retry after 1024 seconds
2021:03:09-23:53:52 xxxxxx-2 repctl[4844]: [e] db_connect(2203): timeout while connecting to database(DBI:Pg:dbname=repmgr;host=198.19.250.1)
2021:03:09-23:53:52 xxxxxx-2 repctl[4844]: [e] master_connection(2045): (timeout)
2021:03:09-23:53:52 xxxxxx-2 repctl[4844]: [i] main(188): cannot connect to postgres on master, retry after 1024 seconds
-----------------------------
Mayby someone knows if it is a UTM 9.705 bug or were postgres database corrupt because of up2date?
is there any possibility to downgrade the reserved UTM 9.705 to UTM 9.605?
P.S. maybe reads it someone from Sophos Support: creating Support Request in sophos support portal failed with message:
Thank you for your registration request. Unfortunately, we are not able to process your request at this time without further information. Please contact the team to help get this resolved. In the meantime you can still access many of our self-service resources like the Sophos Community, product documentation, knowledge base, and Sophos Techvids.
Thanks in advance
This thread was automatically locked due to age.

