Hello,
we have an SG450 cluster (Sophos UTM version: 9.602)
Yesterday we replaced one of the nodes, because there was an raid error displayed.
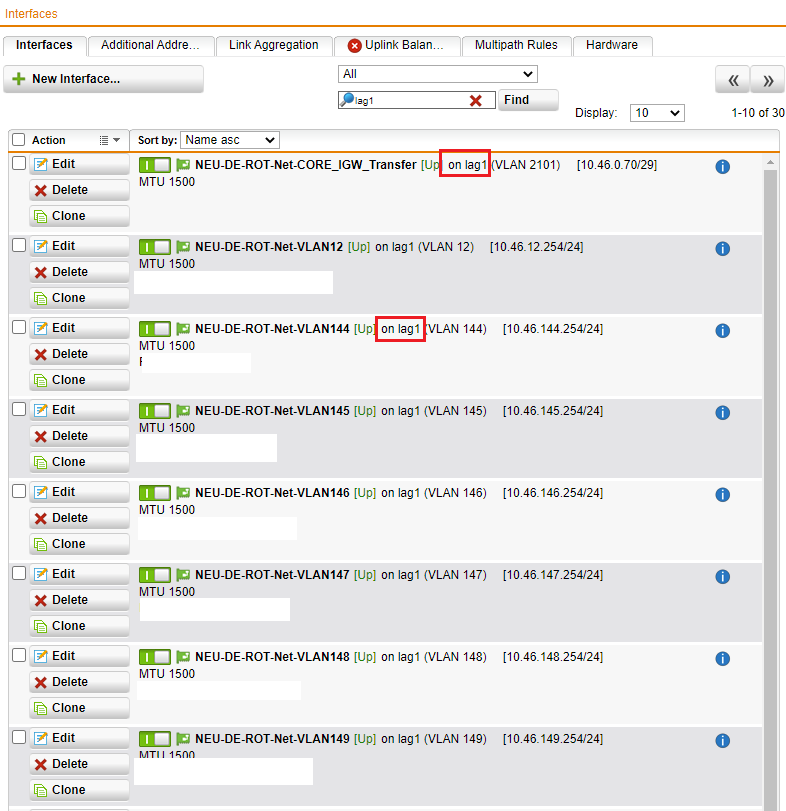
We have two 10 Gbit SFP+ Transceiver in Port E8 + E9. On this both ports is an Link Aggregation group (LAG) defined.
On this LAG are some VLANs mapped (interface type: Ethernet VLAN). So the core routing for the subnets do the Sophos SG450 cluster.
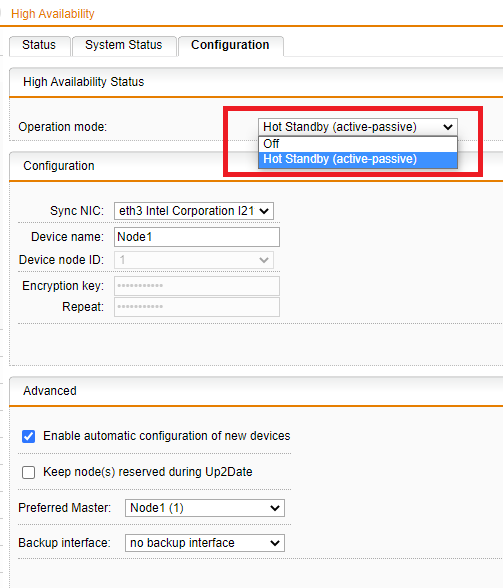
After changing the HA-configuration from: "Hot-Standby (active-passive)" to "off" (for tests),
all Gateway addresses from the VLANs lost connection! (no reaction, no pings etc.)
I accessed then the Sophos via "eth0". After taking each VLAN interface offline and then online again,
the network connections were online again. (pings, network access etc.)
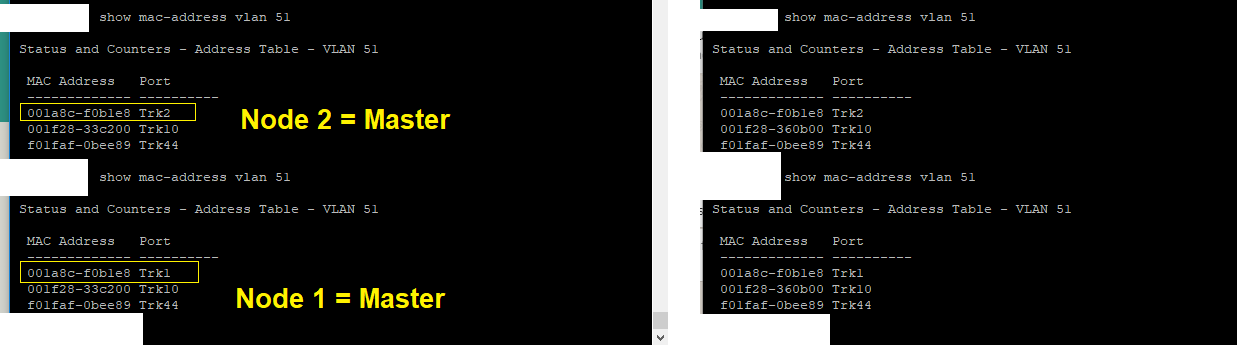
This behaviour can be watched only if i change the HA-config from active-passive to "off".
It seems that the Trunk / LAG have trouble with this and needed to be reactivated.
Can anyone imagine why this happens?
Thansk so far!
This thread was automatically locked due to age.