

Is this bug going to be fixed, or it has become a feature with a workaround?
Workaround
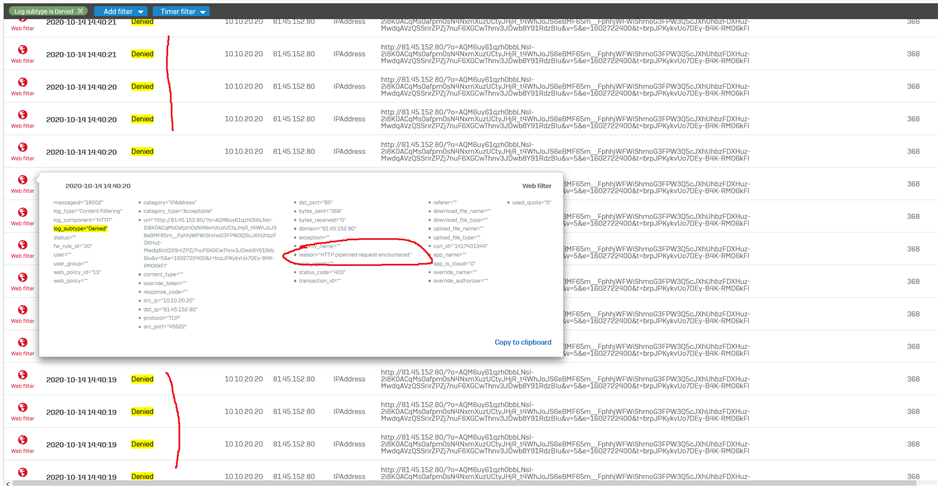
BUG reason="HTTP parsing error encountered."
BUG reason="HTTP pipelined request encountered."
This thread was automatically locked due to age.
Important note about SSL VPN compatibility for 20.0 MR1 with EoL SFOS versions and UTM9 OS. Learn more in the release notes.
Is this bug going to be fixed, or it has become a feature with a workaround?
Workaround
BUG reason="HTTP parsing error encountered."
BUG reason="HTTP pipelined request encountered."

How can we interpret this application? What is this service doing? Its a HTTP webservice.
PS: Michael Dunn posted in one of your Threads:
HTTP pipelining is not supported in DPI mode. It is not commonly used but then we discovered that some netflix are using it. We are working on what we can do.
Seems like your application is doing a pipelining - Which is not supported.
__________________________________________________________________________________________________________________

As LuCar has said, HTTP Pipeline is not supported in DPI mode.
As posted in the EAP threads you mention, but let me clarify.
The HTTP Pipeline error was appearing for some non-pipeline reasons in EAP, which we think are all resolved in GA.
The only HTTP Pipeline errors that we know about are "real" pipelines such as some netflix hardware. The solution it to configure that traffic only to go through the traditional web proxy.
If you are getting the error for specific traffic only then it is likely real a pipeline error, and you should configure it so that traffic goes through the proxy.
If you are getting that error all over the place (like your screenshot during EAP) you may have another problem that is something to do with your network topology, your configuration, or a fault on your box. Given that we are not getting any support calls about this, it is unlikely (but certainly possible) this is a bug, or if it is one it is only in certain uncommon setups.
For example, HTTP pipeline was supported (but disabled) in FireFox and then removed in 2017. Its removed from Chrome as well, not sure when. However if you are using an old browser that still supports it, and enabled pipelining for it, then you may be experiencing HTTP pipeline errors all over the place. At that point the solution is to update/reconfigure your browser/app/whatever is doing that.
If you are getting that error all over the place and you have Sophos Support, please raise a ticket with them.
If you are getting that error all over the place and you don't have Sophos Support, there is not much I can suggest. Maybe install another box, see if it happens there as well.
All this are ussing HTTP pipelined
Microsoft (I have seen it in my log sometimes I think related with windows updates), Blizzard, Netflix, Dyson, Samsung TV App center, Xbox app on windows 10, Panda Antivirus, some android apps.
I dont even have 20 devices at home, considering IoT so I can't image how this is not a huge issue in any company. So it must be commonly used.
Examples of urls considered http pipelined
eu.cdn.blizzard.com/.../a47682f8bdf0a56c95a923946dd9f415
webres1.pand.ctmail.com/.../SpamResolverNG.dll
I am sure is not a problem in my instalation since is a clean one (no backup restore) and diferent HW, before was a VM, and the errors are still the same.
There must be a way to fix the DPI engine, other vendors, don't have this issue, at least checked with palo alto and checkpoint at work using netflix, no issues.
I fully agree that this is a huge issue for your system. But we have thousands of installs of v18 and we are not getting any reports of this problem from other customers. Therefore it most likely a problem with your system. It is also not a problem we can diagnose or fix, because we cannot reproduce it.
I would contact Support. If they cannot resolve it they should escalate until it gets developers and someone on my team will look at your system.
Right now with a thousand customers using DPI representing with hundreds of thousands of end users using DPI, and one customer reporting a problem does not indicate to me that DPI is broken overall, only that it is broken for you.
If other customers are also experiencing this, please mention it here and then open a Support ticket. If this is a widespread problem we want to fix it, which means we need to have developers examine systems that are failing.
I can tell you is a generalized issue, tried in 2 systems differnet HW, the block of http pipelined requests doesn't completely break the service, Netflix still work but worse, Blizzard still download stuff but slowed, etc.
So probably in a company nobody notice this because it only produce a degradation of the service.
Anyway DPI doesn't properly work in general there are hundreds of complains in the forums, this technologies in other vendors just simply work, doesn't require work arounds or break the funtionality as a feature.

Michael Dunn, I don't wish to hijack l0rdraiden's thread, while I'm sure you have thousands of those installs, are you sure they switched from web proxy to DPI?
I ask because I have constant problems every time I try to switch over to DPI from web proxy. I've seen other complaints on here but I get the impression most people just continue to use the web proxy engine for this and don't bother with DPI because they don't want the headache.
I don't have the telemetry for DPI specifically. I think there are now ~60,000 v18 installations. Some percentage of them are using DPI. I know we have a few big customers using DPI.
I want to give you an example of what I see. Yesterday, after upgrading to MR3 I changed a rule that only had a couple of people hitting it to use DPI instead of web proxy. About 3 hours later I got the first call, "I can't get into my AOL e-mail." Now normally I don't care if people can't access their personal e-mail or Facebook or whatever, but since this guy was using DPI I viewed it as the canary in the coal mine and decided to investigate. I discovered that Chrome was telling him "ERR_CONNECTION_RESET." I pulled up the XG log viewer, went to TLS/SSL, and saw no errors. So I then went back to his machine and found the exact URL that was generating this message. Went back to XG and found that entry in the log. XG says it was decrypted fine. Hmmm. I ran a "Policy Test" with all the relevent criteria, the site is allowed and shows that TLS/SSL will Decrypt it. So why in the world is the connection being reset? I have no idea. I added oidc.mail.aol.com (the URL in question) to the Local TLS Exclusion list, and the login page loaded and he was able to get into his e-mail. I also changed the rule back to web proxy, removed that Local TLS Exclusion, and that same URL loads fine, and checking the certificate, is being signed by the MITM XG cert, so XG is definitely decrypting it while using web proxy, but in DPI mode it results in an Reset Connection and no indication in logging that anything went wrong. So as an administrator, I am left with, just sit by the phone and wait for the calls and essentially play whack-a-mole with all the random sites that don't work, for whatever reason. That doesn't work for me.
And there are still plenty of FLOW_TIMEOUT errors (seemingly unrelated to this) that I still have no idea what impact they may be having.
Now you could probably say "Open a support case" and maybe I should. But its way more expedient to just turn all this stuff that doesn't work reliably, off, and move on.
I want to give you an example of what I see. Yesterday, after upgrading to MR3 I changed a rule that only had a couple of people hitting it to use DPI instead of web proxy. About 3 hours later I got the first call, "I can't get into my AOL e-mail." Now normally I don't care if people can't access their personal e-mail or Facebook or whatever, but since this guy was using DPI I viewed it as the canary in the coal mine and decided to investigate. I discovered that Chrome was telling him "ERR_CONNECTION_RESET." I pulled up the XG log viewer, went to TLS/SSL, and saw no errors. So I then went back to his machine and found the exact URL that was generating this message. Went back to XG and found that entry in the log. XG says it was decrypted fine. Hmmm. I ran a "Policy Test" with all the relevent criteria, the site is allowed and shows that TLS/SSL will Decrypt it. So why in the world is the connection being reset? I have no idea. I added oidc.mail.aol.com (the URL in question) to the Local TLS Exclusion list, and the login page loaded and he was able to get into his e-mail. I also changed the rule back to web proxy, removed that Local TLS Exclusion, and that same URL loads fine, and checking the certificate, is being signed by the MITM XG cert, so XG is definitely decrypting it while using web proxy, but in DPI mode it results in an Reset Connection and no indication in logging that anything went wrong. So as an administrator, I am left with, just sit by the phone and wait for the calls and essentially play whack-a-mole with all the random sites that don't work, for whatever reason. That doesn't work for me.
And there are still plenty of FLOW_TIMEOUT errors (seemingly unrelated to this) that I still have no idea what impact they may be having.
Now you could probably say "Open a support case" and maybe I should. But its way more expedient to just turn all this stuff that doesn't work reliably, off, and move on.

One other point at which connections can be shut down, which can behave differently in DPI mode, is IPS. Do you have IPS enabled for those connections and did you check the IPS log to see if any IPS signatures triggered?
To go along with Rich's comment.
You mention looking in the TLS/SSL error log, but not any of the others. Things like pipeline errors and http parsing errors are in the Web Filter log. There may be other things in other logs that could also indicate a problem.
Log Viewer, detailed view, have all components selected. Search for the domain name.
Unfortunately the IPS log does not contain the domain name, because it operates on all traffic regardless of protocol. To include IPS log entries in a search when in detailed view, you'll need to search on the destination IP address, once you've identified that from the TLS or Web Filter logs.
I searched the IPS logs, it is not being blocked by IPS. I searched using Michael Dunn's method, nothing shows as error or denied or failed; according to XG, everything is fine with this traffic. Yet Chrome reports the connection is being reset if the DPI engine is decrypting it. Put in a TLS Exception or switch back to web proxy, and everything works fine.
Look guys, don't get the wrong idea that I am just a disgruntled customer who has an irrational ax to grind against the DPI engine. It sounds great on paper, it has a lot of promise, but last time I enabled it I got a panic call from our HR people who, halfway into trying to post payroll for the week, the site (a standard HTTPS site) just bombed out and they couldn't process payroll. Turned out it was the DPI engine, didn't like a particular page from PrimePay for whatever reason. The guidance has sort of been "well these things happen" and "make an exception when you encounters a problem" and that's just not practical advice in my opinion. It also doesn't help when according to the logs from XG, everything should be A-OK but it clearly is not.
Hi Bill,
Your feedback here is definitely appreciated. Where there are genuine issues we want to track them down and fix them, for sure. Obviously, our guidance to make an exception or switch to proxy mode is geared towards helping keep our customers businesses moving when issues like this crop up, but I well aware that it can appear to mask or downplay when there are genuine problems.
With detailed feedback we can keep digging in to these issues. We already have a number of fixes lined up for MR3, which we just soft-released and for MR4, which we hope to get out before too long.
Regards
Rich
I was doing a little additional testing with the DPI engine and noticed another problem; it breaks YouTube Live videos. They work fine for a while (it varies but rarely more than 10 minutes) but eventually, you get the spinning circle stall. Additionally the live chat just stops updating, but you may not realize it until you refresh and see the thousands of messages you missed. XG logging of course reports no TLS/SSL errors, no firewall rule blocking, no IPS blocking, and switching back to web proxy results in all of these things just fine.
Hi Bill Roland Could you please create a new Thread for this Youtube issue?
As far as i know, this is already tracked but i want to decouple this topic from differnet issues.
__________________________________________________________________________________________________________________