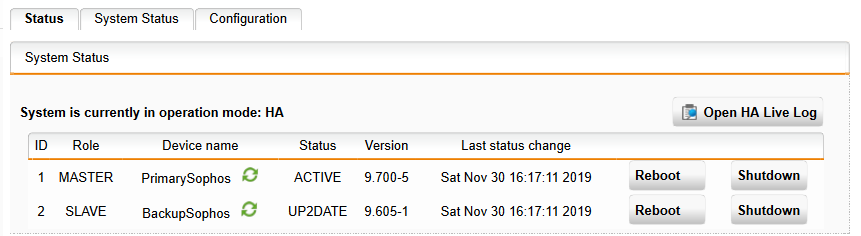
SG 310
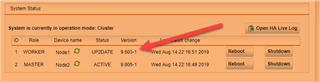
Here is what the live log says....
2019:08:16-09:17:29 epi-colo-fw01-2 repctl[6582]: [i] recheck(1057): got ALRM: replication recheck triggered Setup_replication_done = 1
2019:08:16-09:22:29 epi-colo-fw01-2 repctl[6582]: [i] recheck(1057): got ALRM: replication recheck triggered Setup_replication_done = 1
2019:08:16-09:27:29 epi-colo-fw01-2 repctl[6582]: [i] recheck(1057): got ALRM: replication recheck triggered Setup_replication_done = 1
2019:08:16-09:32:29 epi-colo-fw01-2 repctl[6582]: [i] recheck(1057): got ALRM: replication recheck triggered Setup_replication_done = 1
2019:08:16-09:37:29 epi-colo-fw01-2 repctl[6582]: [i] recheck(1057): got ALRM: replication recheck triggered Setup_replication_done = 1
2019:08:16-09:42:29 epi-colo-fw01-2 repctl[6582]: [i] recheck(1057): got ALRM: replication recheck triggered Setup_replication_done = 1
2019:08:16-09:47:29 epi-colo-fw01-2 repctl[6582]: [i] recheck(1057): got ALRM: replication recheck triggered Setup_replication_done = 1
2019:08:16-09:52:29 epi-colo-fw01-2 repctl[6582]: [i] recheck(1057): got ALRM: replication recheck triggered Setup_replication_done = 1
2019:08:16-09:57:29 epi-colo-fw01-2 repctl[6582]: [i] recheck(1057): got ALRM: replication recheck triggered Setup_replication_done = 1
2019:08:16-10:02:29 epi-colo-fw01-2 repctl[6582]: [i] recheck(1057): got ALRM: replication recheck triggered Setup_replication_done = 1
2019:08:16-10:07:30 epi-colo-fw01-2 repctl[6582]: [i] recheck(1057): got ALRM: replication recheck triggered Setup_replication_done = 1
2019:08:16-10:12:30 epi-colo-fw01-2 repctl[6582]: [i] recheck(1057): got ALRM: replication recheck triggered Setup_replication_done = 1
I was thinking of running auisys.plx --upto 9.605-1
This thread was automatically locked due to age.