I’m documenting my numerous issues with SOPHOS Firewalls so that others can be aware of what they are getting themselves into.
Episode #1
Issue # 2 – Email Alerts, Green Statuses, and Routes
As an administrator, it’s impossible to check every system under our management multiple times a day. So it is very commonplace that systems have alerts that will let you know when something is amiss. Under the SG Firewall, the alerts were very robust, not so for XG.
- For one example I was alerted when anyone signed into a firewall. Under the new XG Firewall, this is not an option.
- On SG if an AP went offline for some reason the alert noted the name of the AP(if you named is) so you’d know right away which AP was offline. On XG, you can name the APs as well, however it only lists the serial number of the AP that went offline. So you now need to go check which AP has that serial number before you can go track it down.
- Same goes for HA Appliances. You have a notification if one goes down and the other becomes primary, and instead of including the name of the device, it tells you (node1) and the serial number. So now you need to go track it down. It includes a whole host of other information you don’t need, and excludes the information you do need. It seems like Joe from shipping\receiving is the one that makes the design choices. And the sad part is they OWN a well-designed product they could steal good ideas from while they design the new OS.
Secondly…
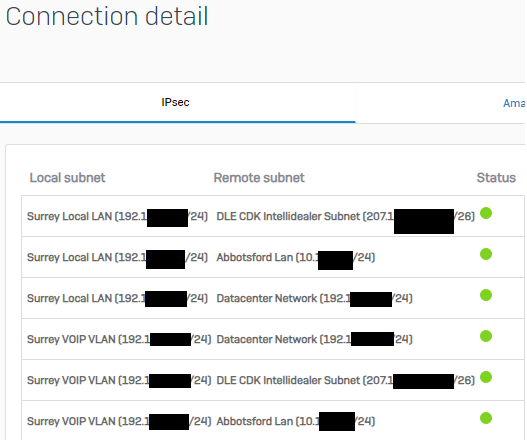
I had a strange routing issue. We have IPSEC VPN Tunnels, and each tunnel has 6 routes. If you go into the VPN connection details, there is a button you can click on and it will show you the routes and a green light beside each, indicating their status. Green means good, Red means bad.
When this issue happened, one of the 6 routes was not working. This VPN had been functioning for 3 months flawlessly and then in the middle of the day, one route stopped working. I proved the behaviour it by confirming that our domain controllers could not be reached(which was also the complaint of staff). I checked the VPN route statuses and they were all green, including the route that was not working. I contacted SOPHOS immediately as I’ve had all sorts of strange issues happen with these firewalls and now I had a live case for them to see.
The tech I spoke with confirmed that the firewall showed all was good (green statuses everywhere), and also confirmed that the route was definitely not working. I knew if I bounced the VPN tunnel the issue would go away, but I didn’t want to touch it as I wanted SOPHOS to see and diagnose the issue.
The first thing the tech wanted to do was see the VPN config, however, when you have your VPNs configured in a failover, you have no way of seeing the VPN configs anymore. Joe from shipping\receiving(who is the Designer for these Firewalls), must have figured it wouldn’t be necessary. I’ve run into this issue multiple times already in 4 months, when I’ve called SOPHOS for support. SOPHOS Techs support want to double check settings and literally can’t without taking our VPN offline. I checked with SOPHOS design people on this, and they assured me it was “by design” and “working as intended”. SOPHOS tech support did not agree.
Next the SOPHOS tech decided to open up a packet capture on the firewall. The second he enabled the packet capture, it caused the routing issue to start working again. Very strange.
After that he grabbed all the logs, however, he was unable to determine the issue because the logs were not in debug mode. So I asked him to put all the logs in debug mode and he said that the firewall would cease to function if he did that. So unless the problem is repeated and recurring, you can’t diagnose it because the logs don’t capture the necessary data in non-debug mode. I’ve had this happen on multiple calls with SOPHOS, where lack of debug mode means “problem not solved, case closed”. I’ve also never experienced this issue with logs being insufficient with the SG Firewalls. Somehow, that logging could capture the necessary info, where XG logging cannot. I’m sure this is “as-designed” too.
So I’m working on my clairvoyance degree now, so that I can ensure we enable debug mode before problems happen. This way we’ll hopefully be able to troubleshoot issues.
This thread was automatically locked due to age.