

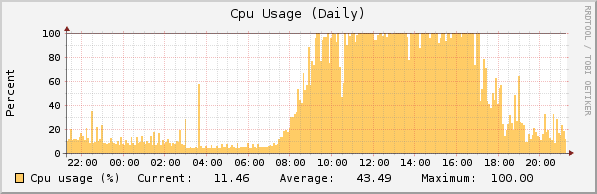
After upgrading ASG120 to 8.201 (now latest 8.202) CPU usage by process postgres increased very dramatically up to 90-100% in peak time.
I disabled Executive Reporting, but no success.
RAM is 1GB (40-50% used)
What else should I try?
This thread was automatically locked due to age.


{kind=link}
{kind=link}