

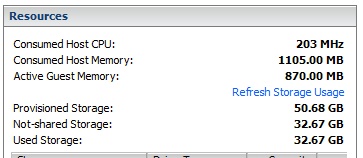
I've included captures from the UTM and ESXi below.
Any suggestions on how I can correct this? Thanks for your help.
/root # df -h --total
Filesystem Size Used Avail Use% Mounted on
/dev/sda6 5.2G 2.3G 2.7G 47% /
udev 501M 72K 501M 1% /dev
tmpfs 501M 0 501M 0% /dev/shm
/dev/sda1 331M 14M 300M 5% /boot
/dev/sda5 17G 4.1G 12G 27% /var/storage
/dev/sda7 22G 678M 20G 4% /var/log
/dev/sda8 1.3G 17M 1.2G 2% /tmp
tmpfs 501M 20K 501M 1% /var/sec/chroot-httpd/dev/shm
tmpfs 501M 80K 501M 1% /var/storage/chroot-reverseproxy/dev/shm
tmpfs 501M 80K 501M 1% /var/storage/chroot-smtp/tmp/ram
total 47G 7.1G 38G 16%
This thread was automatically locked due to age.



{kind=link}