Hi-
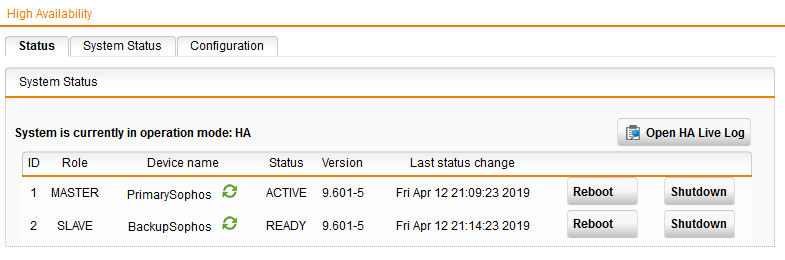
Last night I got an automated email from the Sophos UTM (9.601-5) which is running with a pair of SG125s in HA mode that HA mode was recovered -- just one email. Thats unusual as the only time I get these kinds of emails is during a manual firmware Up2Date and then I get several as the HAs update and synch and go back to production status. I checked HA status and it was fine. Chalked it up to a glitch or momentary hickup.
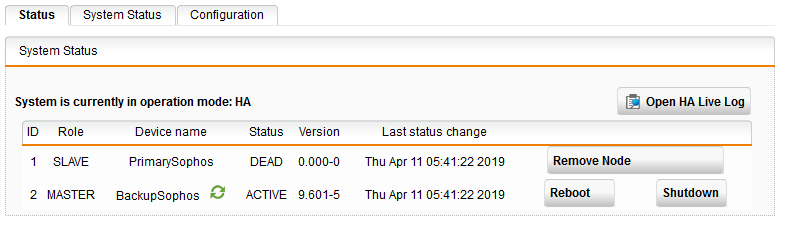
This morning, the Primary device (which is physically 192.168.0.1 and the WebAdmin address) is currently in SLAVE mode with a DEAD status, and I have all kinds of HA automated emails about one UTM being down and the other recovering for it etc etc etc.
As you can see, the BackupSophos (which is physically 192.168.0.20 but now being accessed by LAN's 192.168.0.1 since its now in Master state) is running the show. I checked the boxes and there are lights on both UTMs so the PrimarySophos is not without juice -- status indicator lights are flashing on it just like the backup box (which is now operating in primary mode).
I dont want to screw something up, so what are my first steps to troubleshoot and see if I can get the problematic UTM synched back up properly and in MASTER mode again?
Possible options as I see it:
1. Reboot the BackupSophos in the WebAdmin in the HA panel, but Im not sure this will have any affect on the dead UTM?
2. Physically reboot the problematic box with the power button (it has power to it and appears to have good status lights)
3. Replace the network cable attaching the problematic box to the LAN from eth0 (I see good lights however)
4. Replace the network cable chaining the Primary and Backup boxes from their DMZ ports (I see good lights however).
Not sure what my chess moves should be and in what order. Any advice. I have not done any Firmware Up2Dates recently so I dont believe that would affect anything. Not sure if a automated Pattern Up2Date could cause this or if I legitimately have a malfunctioning Primary UTM.
This thread was automatically locked due to age.