Hi Community,
we had a pretty strange issue with out WAN connection yesterday.
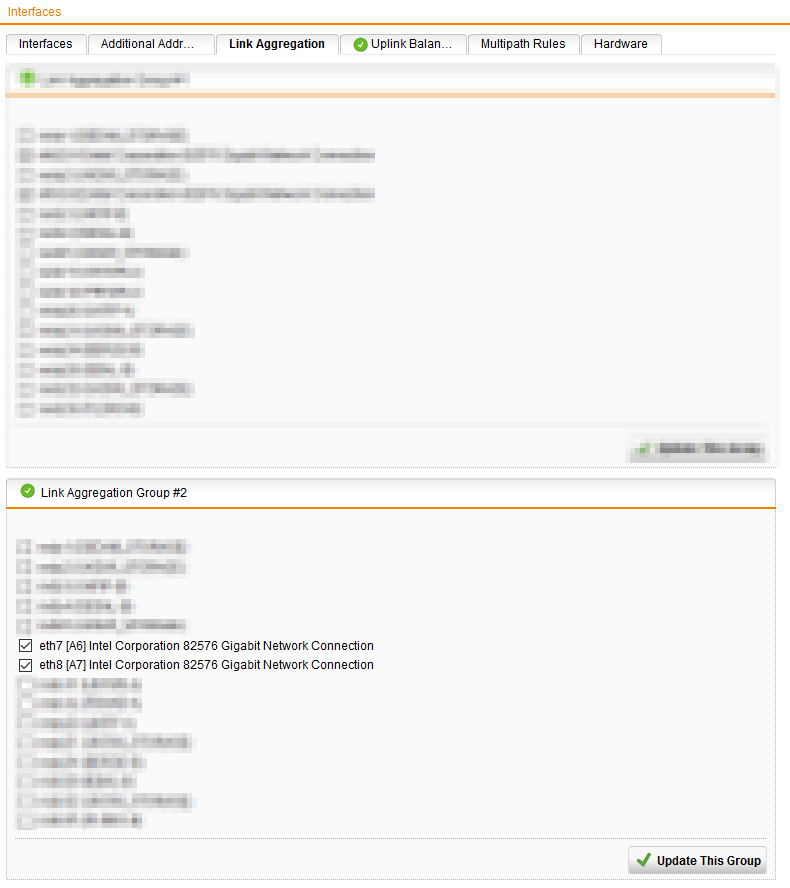
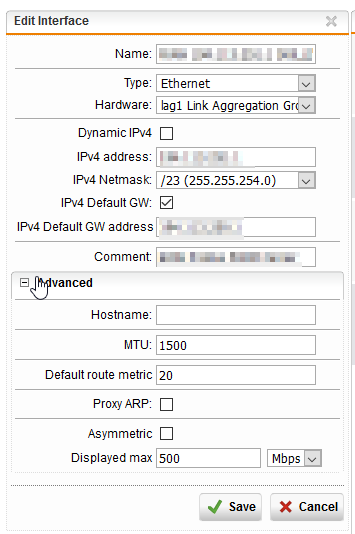
We configured a new LAG on our Sophos SG230.
After hitting the save button within the LAG configuration suddenly our WAN broke down.
And with the WAN a few of our websites that are reachable externally.
The LAG configuration look like the following:
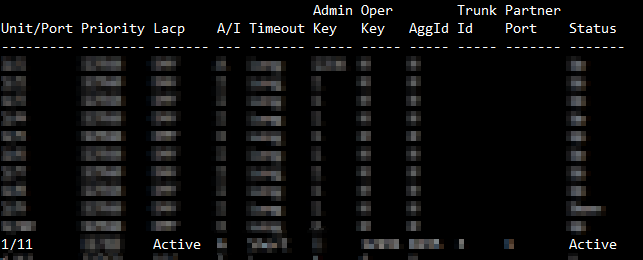
On our switches where the firewall is connected to we also created a lacp config.
We have two ports within the lacp group on our redundant switches that are in a special vlan.
Yesterday we rebooted one of our Sophos SG230 firewalls, after the reboot took place the WAN came up again for a few minutes.
It also seemed like if our Sophos SG230 had some issues with it's WebUI, sometimes it was not reacting to any actions.
The latest firmware version 9.702-1 is installed on our Sophos SG230 cluster.
Please let me know if you have any ideas, hints etc. so we can dig deeper into the root cause analysis.
Many thanks in advance & best regards,
Judith
This thread was automatically locked due to age.